
LiteSpeed Cache WordPress Plugin Configuration Tutorial
LiteSpeed Cache is a caching plugin for WordPress that helps improve the performance of a website…

LiteSpeed Cache is a caching plugin for WordPress that helps improve the performance of a website…

Today’s world is fast-paced and data-driven, where effectively interpreting complex datasets can mean the difference between…

YouTube isn’t just where you go to waste hours watching random stuff—it’s the birthplace of viral…

Are you considering using a virtual number for your WhatsApp Business account? While it might seem…
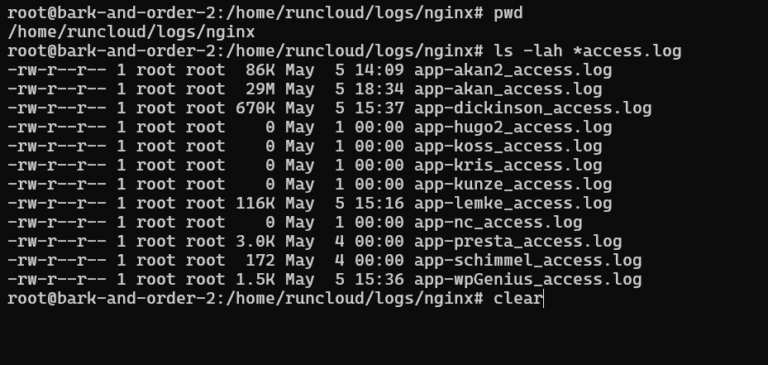
Is your website drowning in WordPress comment spam? If you’re battling endless waves of bot-generated junk,…
Orchestrator comes with many plugins installed by default, including the VC plugin. If you’re using the…

Much like with the acorn example above, we had known what to do—we had just not…
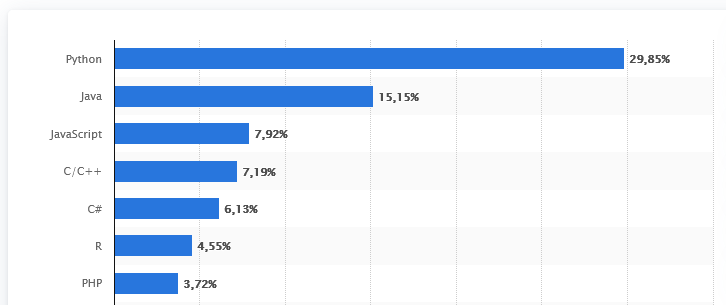
Advantages and Disadvantages of Python and Java Java and Python are among the most widely used…

Get $10 OFF the Ellipal X Card Wallet when you use this link: https://www.ellipal.com/?rfsn=7218162.92e9cb Chapters:0:00 –…

I started building websites in 2006, and like most beginners, I used shared hosting. It was…
Wix, best known for its drag-and-drop website builder, is making a play for the design tool…

🚨 Get 15% OFF your entire Tangem order with this link: https://tangem.com/en/pricing/?promocode=CYBERSCRILLA#pricing Or use my code…

One of Bush’s “points of light” Energy Star was first established under President George H.W. Bush’s…
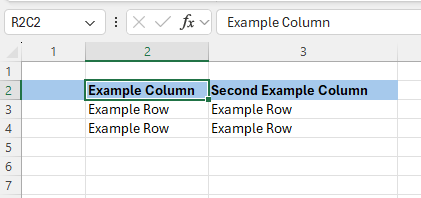
Why Upgrading XLS to XLSX Is Worth Your Time Ask any seasoned Java developer who’s worked…

From freelancer to successful co-founder, Ionut Neagu has worked with WordPress for 13+ years. Along the…