
Why Ghost Buttons are the Ultimate Conversion Killer
The ghost button emerged as the quintessential icon of the flat design era, favored by designers for its…

The ghost button emerged as the quintessential icon of the flat design era, favored by designers for its…

“All of our spacewalks are designed really for two people; the system really isn’t made where…
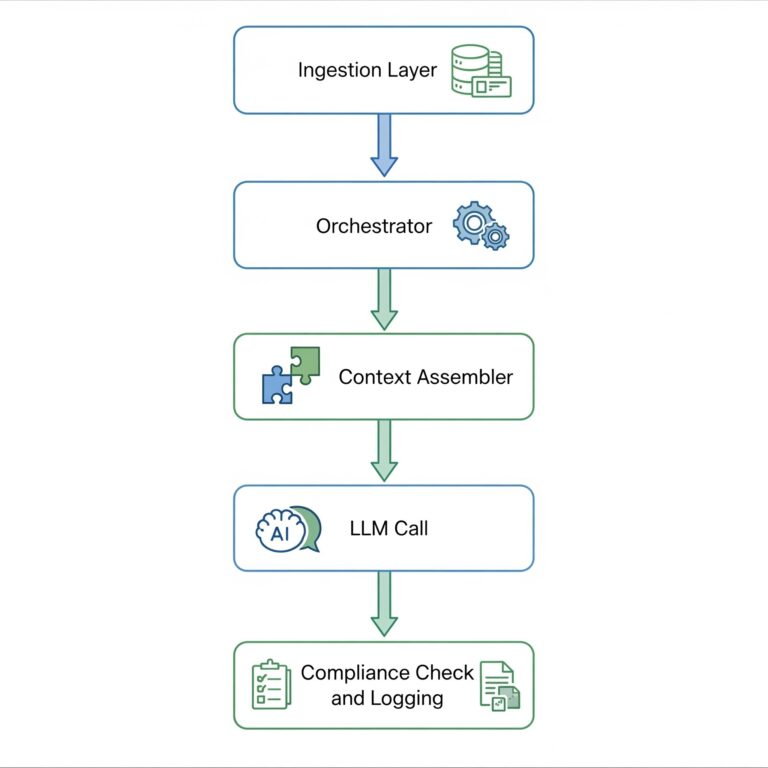
Asking Claude, ChatGPT or any other advanced LLM “What is AI?” produces a well structured response…

Google’s new Googlebook is now competing with Microsoft Windows for the worst budget laptop award. SOURCES…Googlebook…

👍 Wallet Links + Discounts: 1️⃣ S TIER: • Get Tangem (30% off): https://tangem.com/pricing/?promocode=CYBERSCRILLA&promocode=NYEXTRA26 • Get…
Ghost is a sleek, lightning-fast, and modern alternative to WordPress that strips away the bulky plugins…

WordPress 7.0 is finally here 🥳, and we’ve been testing it since the early beta. It’s…

Every WordPress release celebrates an artist who has made an indelible mark on the world of…

Google has given us a glimpse into the AI-first and human-last future at their Google I/O…

For twenty years, WordPress empowered millions of people to build websites. It lowered the barrier, democratized…

For most of the past year, it looked like prediction markets had kicked off a new…

Image classification is now a key part of many applications. Whether you’re automating photo organization, filtering…

Introducing Google’s new Android with Gemini Intelligence! It’s becoming more like iOS… the bad parts. Original…

Tangem Deal: https://tangem.com/pricing/?promocode=CYBERSCRILLA&promocode=NYEXTRA26

If you woke up to news that StellarWP is being dissolved as a brand, you probably…