Suppose you want a chatbot that works with PDFs: extract text, search across documents, summarize sections. You can build it two ways: by calling an LLM API directly and wiring tools yourself, or by exposing those tools through the Model Context Protocol (MCP). Same user experience — different architecture. This article uses a PDF example to walk through both routes and explain what MCP adds.
The Goal
User asks in natural language → chatbot reads/searches PDFs → returns an answer.
Example prompts:
- “What’s in the introduction of report.pdf?”
- “Search all PDFs in ./docs for ‘quarterly revenue'”
- “Summarize the key points from these three documents”
Same behavior either way. The difference is how the chatbot gets PDF capabilities.
Route 1: LLM + API (You Own the Loop)
In this approach, your app talks directly to the LLM API (Claude, GPT, etc.), defines tools as part of each request, and runs the agentic loop yourself. You implement the PDF logic and you decide when to call it.
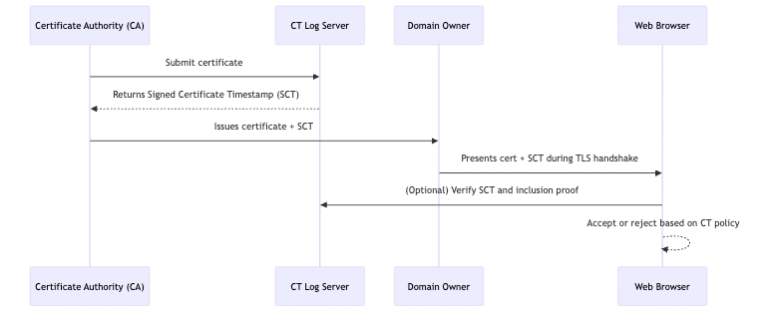
Architecture
┌─────────────────────────────────────────────────────────┐
│ Your App (single process) │
│ │
│ ┌──────────────┐ tools + messages ┌──────────┐ │
│ │ Agentic Loop │ ──────────────────────► │ LLM API │ │
│ └──────┬───────┘ └──────────┘ │
│ │ │
│ │ tool_use │
│ ▼ │
│ ┌──────────────┐ │
│ │ executeTool()│ ──► read_pdf, search_pdf, extract_text │
│ └──────────────┘ (your code, same process) │
└─────────────────────────────────────────────────────────┘You define the tools, send them with every API call, and when the model returns tool_use, you run the matching function and feed the result back.
PDF Tools (Inline)
const tools = [
{
name: "read_pdf",
description: "Extract full text from a PDF file",
input_schema: {
type: "object",
properties: { path: { type: "string", description: "Path to the PDF" } },
required: ["path"]
}
},
{
name: "search_pdf",
description: "Search for a keyword across PDFs in a directory",
input_schema: {
type: "object",
properties: {
directory: { type: "string", description: "Directory containing PDFs" },
keyword: { type: "string", description: "Search term" }
},
required: ["directory", "keyword"]
}
},
{
name: "list_pdfs",
description: "List all PDF files in a directory",
input_schema: {
type: "object",
properties: { path: { type: "string", description: "Directory path" } },
required: ["path"]
}
}
];
// You maintain the dispatch
async function executeTool(name, input) {
if (name === "read_pdf") return await extractTextFromPdf(input.path);
if (name === "search_pdf") return await searchPdfs(input.directory, input.keyword);
if (name === "list_pdfs") return await listPdfFiles(input.path);
throw new Error(`Unknown tool: ${name}`);
}In the agentic loop, when the API returns stop_reason: "tool_use", you call executeTool(block.name, block.input) and append the result as a tool_result message. Loop until stop_reason: "end_turn".
What This Route Gives You
- Single process — one app, no subprocesses
- Full control — you own the loop, tool definitions, and execution
- Straightforward — just the LLM SDK and a PDF library (e.g.
pdf-parse) - Tight coupling — only this app can use these PDF tools
Route 2: MCP (Protocol + Tool Server)
In this approach, you build a PDF MCP server that exposes the same operations as tools. Your chatbot (or Cursor, Claude Desktop, etc.) connects to it, discovers the tools at runtime, and sends tool calls over the protocol. The server runs the PDF logic; the client only orchestrates.
Architecture
┌─────────────────────────────────────────────────────────────────────────┐
│ Client (chatbot, Cursor, Claude Desktop, etc.) │
│ │
│ ┌──────────────┐ tools/list, tools/call ┌──────────────────────┐ │
│ │ MCP Client │ ◄────────────────────────► │ PDF MCP Server │ │
│ └──────┬───────┘ (JSON-RPC over stdio) │ (separate process) │ │
│ │ └──────────┬───────────┘ │
└─────────┼──────────────────────────────────────────────┼───────────────┘
│ │
│ messages + tool_use │ read_pdf,
▼ │ search_pdf,
┌─────────────────────────────────┐ │ list_pdfs
│ LLM API (Claude, GPT, etc.) │ │
└─────────────────────────────────┘ ▼
┌───────────────────┐
│ PDF filesystem │
│ (your machine) │
└───────────────────┘The MCP server is a separate process that speaks the Model Context Protocol. Clients connect (e.g. via stdio or HTTP), call tools/list to discover tools, and tools/call to run them. The client then passes tool results to the LLM and continues the conversation.
MCP Server: PDF Tools
The client never defines these tools. It discovers them:
// chatbot.js — connects to MCP, discovers tools
const mcp = new Client({ name: "chatbot", version: "1.0.0" });
await mcp.connect(new StdioClientTransport({
command: "node",
args: ["pdf-mcp-server.js"]
}));
const { tools } = await mcp.listTools(); // No hardcoding
// When LLM returns tool_use:
const result = await mcp.callTool({
name: block.name,
arguments: block.input
});What MCP Adds
| Concept | LLM + API | MCP |
|---|---|---|
| Tool definition | Hardcoded in your app | Declared in server, discovered by client |
| Tool execution | Your executeTool() |
Server runs it; client sends tools/call |
| Who can use the tools? | Only your app | Any MCP client (Cursor, Claude Desktop, your chatbot) |
| Protocol | Ad hoc (your loop) | JSON-RPC (tools/list, tools/call) |
| Boundary | Everything in one process | Clear split: client = chat, server = tools |
MCP introduces a protocol between the AI client and the tool provider. The client doesn’t need to know how PDFs are read; it just calls tools/call with a name and arguments. The server implements the logic. Add a new tool — e.g. summarize_pdf — and all connected clients see it without code changes.
Using the PDF Example to Explain MCP Further
1. Separation of Concerns
LLM + API: Your app does everything — chat, tool dispatch, PDF handling. One codebase, one deployable.
MCP: The PDF server is a standalone service. It can be developed, tested, and versioned independently. The chatbot (or any client) only needs to know how to speak MCP.
2. Discovery Instead of Configuration
LLM + API: You manually add each tool to your tools array and to executeTool. New tool = update client code.
MCP: The client calls tools/list and gets the current set of tools. Add summarize_pdf to the server — clients automatically have it. No client changes.
3. Reuse Across Clients
LLM + API: If you want Cursor or Claude Desktop to use your PDF tools, you must integrate with each client separately (if they support it at all).
MCP: The same PDF server works with Cursor, Claude Desktop, VS Code Copilot, and your own chatbot. One server, many consumers.
4. Transport Flexibility
MCP supports stdio (subprocess) and HTTP. Your PDF server can run locally as a subprocess or be deployed as an HTTP service. The protocol stays the same; only the transport changes.
When to Use Which
Use LLM + API when:
- You have a single app (internal tool, custom chatbot)
- You want minimal setup — one process, one deploy
- Only this app needs PDF (or whatever) capabilities
- You prefer to own the entire flow
Use MCP when:
- Multiple clients should use the same tools
- You want a reusable “PDF assistant” others can plug into
- You value a clear boundary between tool provider and chat client
- You’re building toward an ecosystem of composable AI tools
How External LLM Tools Call MCP — and Why It Helps
When you expose tools via MCP, any LLM-powered app that speaks the protocol can connect to your server and use them — without you writing a single line of integration code.
The Connection Flow: From Natural Language to the MCP Server
Trace the path — from your typed question to the MCP server that runs the tool:
- User asks in natural language — e.g. “What’s in report.pdf?”
- Client sends the question to its LLM — Cursor, Claude Desktop, or Copilot forwards your message to Claude, GPT, etc.
- LLM decides it needs a tool — It infers you want to read a PDF and chooses
read_pdf(path: "report.pdf"). - Client sends
tools/callto the MCP server — The client does not run the tool itself. It sends a JSON-RPC request to your MCP server. - MCP server receives the call — Your
pdf-mcp-server.jsgets the request, runsread_pdf, extracts the text. - Server returns the result — The MCP server sends the extracted text back to the client.
- Client passes the result to the LLM — The LLM receives the PDF content, formats a natural-language answer.
- User sees the answer — “The report covers Q3 revenue, product updates, and forecasts…”
So: Natural language → LLM intent → tool choice → tools/call → MCP server executes → result flows back → LLM formats → user sees the answer.
The external tool never implements PDF logic. It only needs to speak MCP: receive tool calls, forward them to your server, and return results.
What Must Be in Place First (Setup)
Before that flow can happen, the client must know which tools exist and where to send calls:
- User configures the MCP server in their client — they point to
node pdf-mcp-server.js(stdio) orhttps://your-pdf-mcp.example.com(HTTP). - Client starts or connects to the server and sends
tools/list. - Server returns the tool schemas —
read_pdf,search_pdf,list_pdfs, etc. The client stores these so the LLM knows what tools are available when it interprets the user’s question.
Once that setup is done, every natural-language question follows the path above: NL → LLM → tool choice → tools/call → MCP server.
Benefits for External LLM Tools
| Benefit | What it means |
|---|---|
| Zero integration | Cursor, Claude Desktop, Copilot, etc. already support MCP. They don’t need a custom plug-in for your PDF server — they use the same protocol for every MCP server. |
| Vendor neutrality | Your PDF MCP server works with any MCP client. You’re not tied to one vendor’s SDK or approval process. |
| Install and use | Users add your server to their MCP config (e.g. ~/.cursor/mcp.json or .vscode/mcp.json) and get your tools immediately. No forking, no wrapping. |
| Same tools, many UIs | One PDF server powers chat in Cursor, in Claude Desktop, and in your own chatbot. Build once, reuse everywhere. |
What You Provide vs. What the Client Does
| You provide | The external LLM tool does |
|---|---|
| MCP server binary or URL | Connects and discovers tools |
| Tool implementations (read, search, etc.) | Translates user intent into tool calls |
| Schema (parameters, descriptions) | Passes tool results back to its LLM |
| — | Renders the conversation to the user |
You focus on making your PDF tools correct and useful. The external tool focuses on conversation and UX. MCP is the contract between the two.
The Bottom Line
LLM + API is the direct path: you call the model, define tools, run them yourself. Simple and sufficient for one app.
MCP is the protocol path: you expose tools in a server, clients discover and call them. More moving parts, but you gain discovery, reuse, and a standard interface.
The PDF example shows the same capabilities — read, search, list — implemented two ways. Use it to decide where your next project belongs: tight and self-contained (LLM + API) or open and reusable (MCP).