As machine learning programs require ever-larger sets of data to train and improve, traditional central training routines creak under the burden of privacy requirements, inefficiencies in operations, and growing consumer skepticism. Liability information, such as medical records or payment history, can’t easily be collected together in a place due to ethical and legal restrictions.
Federated learning (FL) has a different answer. Rather than forwarding data to a model, it forwards the model to the data. Institutions and devices locally train models on their own data and forward only learned updates, not data.
Not only does this preserve confidentiality, but it also allows collaboration between once-siloed parties.
Understanding the Problem
Centralized data pipelines have powered many of AI’s biggest advances; however, the approach comes with significant risks:
- Privacy breaches: Anonymized data can be re-identified. Medical information, financial information, and personal communications are extremely sensitive.
- Regulatory restrictions: Legislation such as GDPR, HIPAA, and India’s DPDP Act place severe limits on data collection, storage, and transmission.
- Operational inefficiency: Copying data across terabytes of data across networks is time-consuming and costly.
- High infrastructure costs: Storing, securing, and processing massive centralized datasets requires expensive infrastructure, which smaller institutions cannot afford.
- Bias amplification: Central stores will over-represent specific groups or institutions, and thus the models trained will generalize less well than they might across numerous real-world contexts.
These requirements render centralized training impossible in most real-world scenarios.
A New Paradigm: Federated Learning
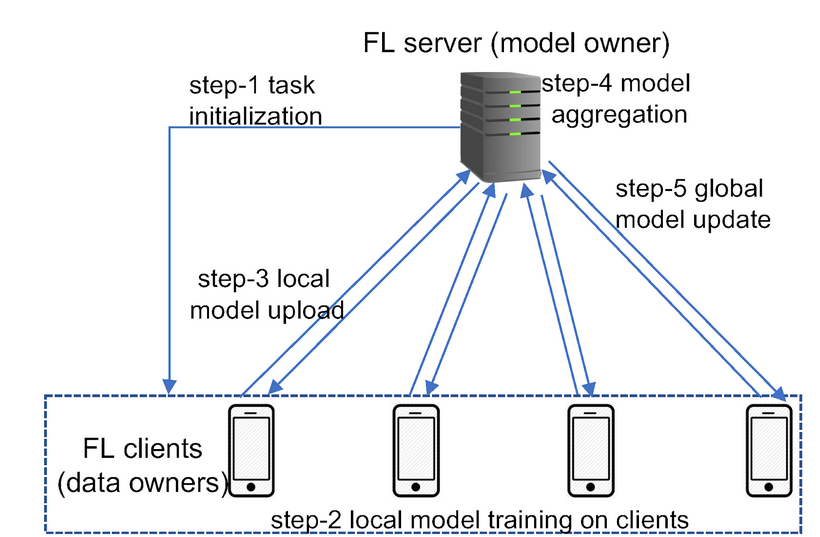
Federated learning (FL) reverses the traditional pipeline on its head. Rather than raw data being accumulated at a central point, the model is installed on every one of the clients (device, hospital, or institution). Training happens locally, and only the resulting model updates, like weights or gradients, are communicated back.
The diagram below shows the FL workflow: Clients train models locally and share the updates with the central server, which combines the updates into a global model.
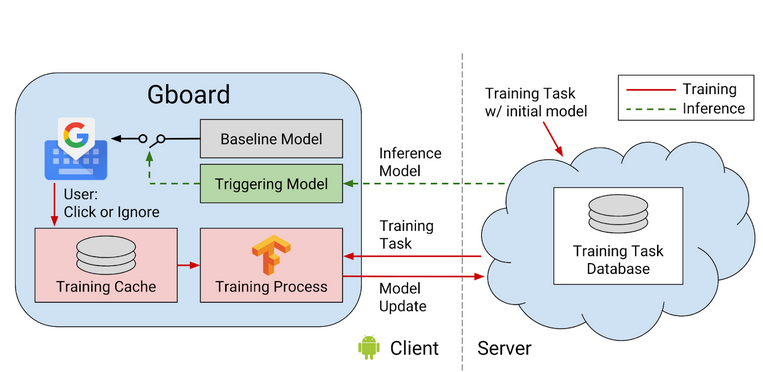
Google first used this strategy in 2016 to enhance Gboard’s next-word predictions without compromising user keystrokes. The keyboard learns in-device locally and sends only model updates, which are compiled into one global model. This, over time, enabled Google to enhance predictive accuracy on millions of devices — never once at the expense of personal keystrokes.
With that breakthrough, FL gained traction. The Federated Averaging (FedAvg) algorithm used in the 2016 Google paper forms the backbone of the majority of contemporary FL systems. Researchers addressed the communication overhead and privacy challenge by 2018 using compression schemes and secure aggregation. FL entered sensitive domains like healthcare, finance, and pharmaceuticals starting from 2019, where collaboration is based on strict data privacy.
By making sensitive information remain at its origin, federated learning takes this concept beyond the mobile keyboard to make collaborative intelligence between previously separate silos possible — opening new possibilities without sacrificing privacy.
“Federated learning is not a single recipe, but a flexible framework that adapts to how data is distributed — across users, features, or domains.” Peter, 2019
Built for Privacy
Federated learning is made privacy-first. Raw data never has to travel from the source; training is always local on devices or institutional servers. This design makes FL by default GDPR and HIPAA compliant for organizations to be able to innovate without breaking data laws.
Most importantly, FL unleashes the value of time-honored silos such as hospital records or bank transaction histories that could not previously be centralized for fear of privacy violations. Meanwhile, it scales seamlessly, syncing training across millions of devices in real-time.
Since sensitive information is held distributed, the system is much less susceptible to breaches; a breach on one server can’t compromise the entire database. Lastly, FL allows personalization without trading off privacy. Local models learn about specific behavior — keyboard use or speech patterns — while the aggregate global model keeps getting better for all.
One interesting case study is healthcare: one group of hospitals used FL to forecast sepsis risk. Each hospital learned locally and exchanged only anonymized information, which generalized to better predictive performance in all hospitals, without compromising patient privacy compliance whatsoever (Rodolfo, 2022).
Since data is local, public updates can still leak sensitive patterns. Differential privacy (DP) comes to the rescue by introducing controlled noise and making it difficult to backtrack updates to users.
Secure multi-party computation (SMPC) and homomorphic encryption (HE) secure updates at aggregation time in a way that no one, not even the server, knows raw contributions.
Adversarial attacks are still a problem: model poisoning allows for malicious updates to be injected, and inference attacks could try to elicit confidential information. Defense approaches involve strong aggregation rules, anomaly detection, and privacy-preserving methods that can balance security and the usefulness of the model.
Types of Federated Learning
Federated learning is not a one-size-fits-all. It relies on the data distribution of institutions. At times, various groups gather similar information about different users, at times they gather distinct information about comparable users, and at times even users and features overlap partially. For addressing all these scenarios, federated learning is specifically categorized into three categories: horizontal, vertical, and transfer learning.
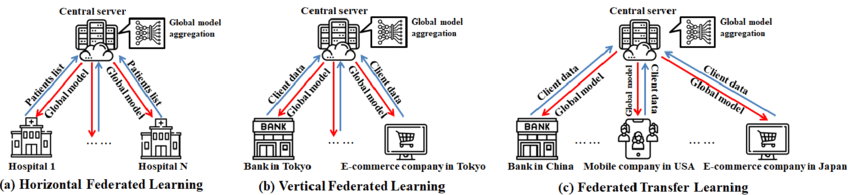
Horizontal Federated Learning
Horizontal federated learning is where there are multiple organizations whose data possess the same features, but over different user groups. For instance, various hospitals can benefit from the same patient information — e.g., age, blood pressure, and glucose level — but from different patient groups. With models learning locally and transmitting parameter updates (not data), organizations can jointly construct a better global model without sharing information, but still better generalized (Jose, 2024).
Vertical Federated Learning
Vertical federated learning involves various organizations having the same clients but extracting unique features. For example, a bank may have a customer’s money history, and an e-commerce firm may have the same customer’s purchase history. They can merge such complementary data sets through safe channels to train jointly shared models without revealing raw data. Such a process provides strong use cases like fraud detection, risk assessment, and credit scoring (Abdullah, 2025).
Federated Transfer Learning
Federated transfer learning is a dedicated method for the scenario where the parties share predominantly disjointed datasets with minimal intersection of both users and features. For instance, one entity might possess imaging data while the other entity possesses laboratory data across various patient groups. Even with minimal intersection of data, federated transfer learning facilitates cooperation among institutions through the potential of transferring acquired representations using federated model updates without sharing sensitive raw data.
According to Wei Guo (2024), his approach generalizes federated learning to geographically scattered and heterogeneous settings, and thus enhances privacy-preserving collaboration across industries and various research domains.
Local models learn about specific behavior — keyboard use or speech patterns — while the aggregate global model keeps getting better for all.
One interesting case study is healthcare: one group of hospitals used FL to forecast sepsis risk. Each hospital learned locally and exchanged only anonymized information, which generalized to better predictive performance in all hospitals, without compromising patient privacy compliance whatsoever (Rodolfo, 2022).
How Federated Learning Works
Federated learning (FL) is a distributed machine learning pattern where many clients — i.e., phones, hospitals, or companies — train models on local data locally. Raw data are not uploaded to some middleman server; model updates are uploaded instead.
Step 1: Client Selection and Model Initialization
The middleman server initializes the global model and chooses the qualifying clients (available, not busy, and have enough data).
Step 2: Local Training
They train the model acquired on local data with common algorithms like mini-batch gradient descent.
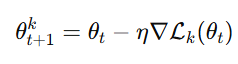
Optional privacy protection: secure enclaves (hardware-based protection) or differential privacy (add noise).
Step 3: Model Update Sharing
Raw data is not sent by clients; instead, parameter updates (gradients/weights) are sent. These may be encrypted or masked through secure aggregation.
Step 4: Central Aggregation (FedAvg)
The server aggregates client updates with Federated Averaging (FedAvg):
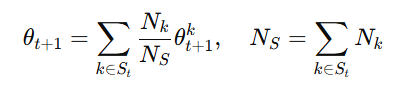
where Nk is the size of client k’s dataset.
Asynchronous or hierarchical aggregation can be used by large-scale deployments for efficiency.
Step 5: Global Model Distribution and Iteration
The newly generated global model is re-distributed to perform another round of training. The iteration continues until the model converges or reaches performance targets.
Example in Practice
Google’s “Hey Google” voice query uses FL such that voice data is locally processed on every phone. Phones transmit only model updates — not the sound itself — guaranteeing better models without sacrificing privacy (Jianyu, 2021).
Core Technical Components
Federated learning enables multiple decentralized clients to collaboratively learn machine learning models without sharing raw data. The distributed model draws on several technical components that manage computation, communication, aggregation, and security. In total, the federated learning paradigm is scalable, efficient, and privacy-preserving because of the synergy among these constituent pieces.
1. Federated Averaging (FedAvg)
It is in the core of federated learning that Federated Averaging (FedAvg) works. In it, every client locally trains the model on its data and sends parameter updates to a central server, but not the model. The server combines these updates — most commonly by averaging — into the global model. The process is iterated over training rounds until convergence.
The following excerpt mentions the essential steps: local training on client-side data, transmitting updates independently (but not original data) to the server, and the server averaging updates to refine the global model accuracy.
global_model = initialize_model()
for round in range(num_rounds):
client_weights = []
client_sizes = []
# Each client trains locally
for client in clients:
local_model = copy(global_model)
local_data = client.get_data()
# Local training (e.g., a few epochs of SGD)
local_model.train(local_data)
# Collect weights and data size
client_weights.append(local_model.get_weights())
client_sizes.append(len(local_data))
# Weighted average aggregation
total_size = sum(client_sizes)
avg_weights = sum((size/total_size) * weights
for size, weights in zip(client_sizes, client_weights))
# Update global model
global_model.set_weights(avg_weights)
print(f"Completed round {round+1}, global model updated.")
2. Synchronization Mechanisms
There are two approaches to synchronizing updates to the model:
- Synchronous training: The server remains idle until all clients have completed and averaged their updates. It provides consistency but can add delays based on slower devices (the “straggler problem”).
- Asynchronous training: The server updates as they come in, accomplishing work faster but occasionally working with slightly out-of-date parameters.
3. Client Devices
Clients form the backbone of federated learning. They may range from smartphones and IoT devices to large enterprise servers. Each client trains models locally on private data and shares only updates, which helps protect privacy while also capturing the diversity of non-IID (non-identically distributed) datasets across participants.
4. Central Server (Aggregator)
The aggregator handles training. It provides the initial global model, collects updates from customers, combines them, and redisperses the improved model. It will also have to deal with real-world challenges such as customer dropouts, varying hardware capabilities, and imbalanced participation levels.
5. Communication Efficiency
Since federated learning runs in the majority of situations on bandwidth-constrained devices and networks, communication overhead needs to be minimized. Methods such as model compression, sparsification, and quantization reduce data transmission costs at the same model performance.
6. Handling Heterogeneity
Client devices are highly heterogeneous across data distribution, computation, and network stability. To address this, methods such as personalized federated learning and FedProx optimization enable models to perform well under dynamic conditions, promoting fairness and robustness.
7. Fault Tolerance and Robustness
Lastly, federated learning systems are made resilient to failure and even active malicious attempts. Techniques like client sampling, dropout management, anomaly detection, and reputation ratings ensure dependability even in turbulent environments.
Efficiency Techniques
Federated learning minimizes communication costs through methods that compress model updates. Sparsification, quantization, and compression reduce data size without sacrificing model accuracy so that training can be done even in low-bandwidth devices.
Compression
Compression methods minimize the size of model updates transferred between clients and the server by representing information less redundantly. Predictive coding, for instance, removes redundancy in model gradients, substantially reducing communication costs without compromising learning performance.

Quantization
Quantization reduces communication overhead by approximating the model weights or gradients with fewer bits, such as 8-bit values rather than standard 32-bit floats. Recent methods introduce error compensation methods to maintain the loss of precision as minimal as possible, which makes quantization a viable solution for bandwidth-limited federated learning systems.
Sparsification
Sparsification lowers communication load by sending only the most substantial model updates, leaving out smaller gradient updates that don’t have much to add to the improvement of the model. In practice, this selective sending greatly lowers overhead and, coupled with quantization, can provide even more drastic compression ratios.
Building a Privacy-First Future
Federated Learning is not only a method of training models when no raw data is available, but also a reinvention of the data, collaboration, and trust management in AI systems.
Data Sovereignty
By retaining information about the originating institution or machine, FL can satisfy highly restrictive privacy regulations such as GDPR and HIPAA, as well as enable multi-country cooperation without opening sensitive data to transparency.
NVIDIA, together with King and College London and Owkin, used FL to train brain tumor segmentation models in different hospitals. Each site was trained locally on MRI scans retrieved in the BraTS 2018 dataset and shared only anonymized updates, which are made more private by using a differential privacy technique. The federated method scored excellent accuracy as the centralized training approach did, yet patient information did not leave hospital servers. This clearly indicates that the ability to recognize a given face lies within the realm of medicine (NVIDIA & King’s College London, 2019).
Democratizing AI
Small institutions and edge devices can also be trained on-site with shared models. Since there are already examples of such devices, such as the Gboard created by Google, it is clear that they have the potential to help millions of devices enhance the system, without centralizing their data.
Robustness and Security
Federated learning enhances protection by introducing techniques such as secure aggregation and differential privacy. These make sure that even the minute model change sent by devices cannot be decompiled. That is, hackers or even the central server are not able to piece together sensitive local data using the shared parameters.
Fairer Representation
FL learns across a variety of decentralized data points and therefore minimizes the bias that would otherwise come with training on small-scale centralized data. This increases the representativeness of models across the various populations, enhancing equity in areas like health care, financial services, and education.
Conclusion
Federated learning proves that privacy and performance need not be at odds. By keeping data where it originates while still enabling collective intelligence, FL addresses some of AI’s hardest challenges: compliance, trust, fairness, and security. From millions of smartphones refining predictive keyboards to hospitals jointly improving patient outcomes, the technology is already reshaping how intelligence is built.
The future of AI is no longer a matter of tearing down privacy fences but of constructing intelligent systems behind them. Federated learning is not merely a technical solution — it is a roadmap to a safer, more democratic, and more representative artificial intelligence future.