
Financial crimes are a persistent threat to financial institutions. Financial institutions have to build risk management systems that can detect and prevent malicious activities. The evolution of cloud computing has enabled leveraging computing power for machine learning in risk management functions like anti-money laundering.
Risk management in financial institutions will primarily focus on identifying, assessing, maintaining, and monitoring various risks. This is very important to ensure compliance with regulatory requirements and stability of the institution to maintain investor confidence. Each institution will have its own structure and process to define adherence to different types of risk functions. Most of the risk functions will involve the following steps:
- Identification: Defining and uncovering potential risks, including their root causes.
- Assessment and analysis: Evaluating the likelihood and potential impact of risks to prioritize mitigation efforts.
- Mitigation: Implementing strategies to reduce risk exposure and minimize the likelihood of incidents.
- Monitoring: Continuously testing, collecting metrics, and addressing emerging trends to ensure the effectiveness of controls.
- Reporting: Generating reports on the progress of risk management initiatives to provide a dynamic view of the bank’s risk profile.
Most risk functions involve judgment from the users. A key risk management strategy would be to automate repetitive processes as much as possible and provide diverse data points using machine learning and AI, allowing risk users to focus on key tasks that require judgment.
Data is the foundation of any machine learning project. One of the key considerations is the availability of high-quality data, as data quality plays a vital role in identifying and mitigating financial crimes.
Why data quality is important:
- According to Gartner, organizations in the financial sector experience an average annual loss of $15 million due to poor data quality.
- Data quality and integrity are a critical challenge 66% of banks struggle with data quality, gaps in important data points, and some transaction flows not being captured at all.
What Are the Possible Data Quality Challenges?
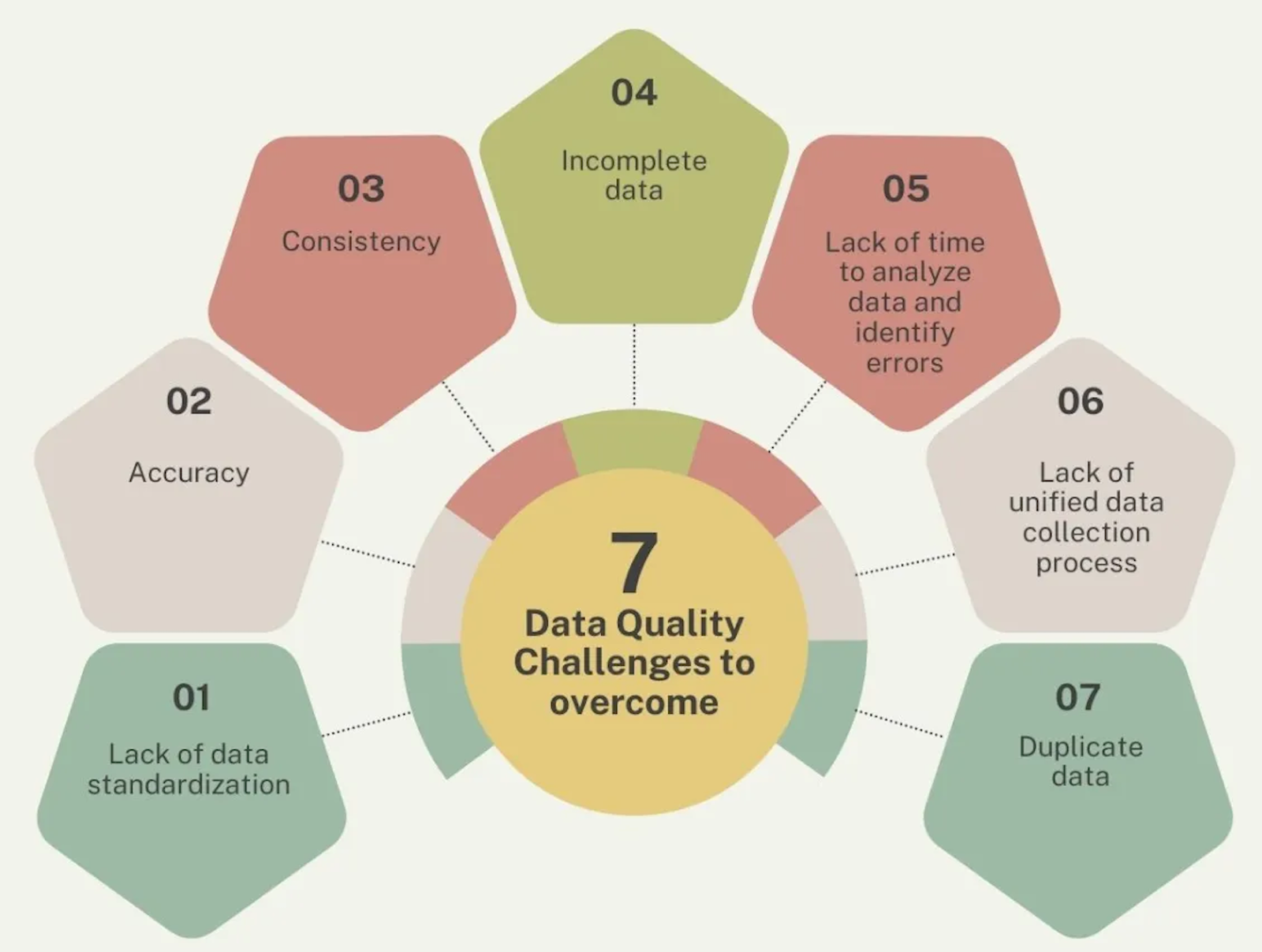
1. Lack of Data Standardization Across the Enterprise
- Different systems across the enterprise may have data in various formats. For example, key data elements may have been defined using different data types across systems.
- This can cause issues in merging the data if required.
2. Accuracy and Completeness
Data might not be complete or missing. If the data is not complete, then it can lead to issues in reporting, which may lead to financial penalties.
- If data updates are not reflected across all systems, it may lead to using incorrect data for compliance purposes.
- Machine learning models may need data from past years, which might not have been updated or may be in different formats.
What Are the Ways to Solve These Challenges?
1. Define Data Management Policies and Enforce the Policies
-
Enterprises can look to define data management policies to define standards on how datasets and data elements should be defined.
2. Technology Investment
- With the onset of cloud computing, building cloud native solutions that can allow for data lineage tracking, real-time validation, and anomaly detection.
- Building a technology ecosystem to ensure adherence to data management policies throughout the data life cycle.
Let’s look at the reference architecture below:
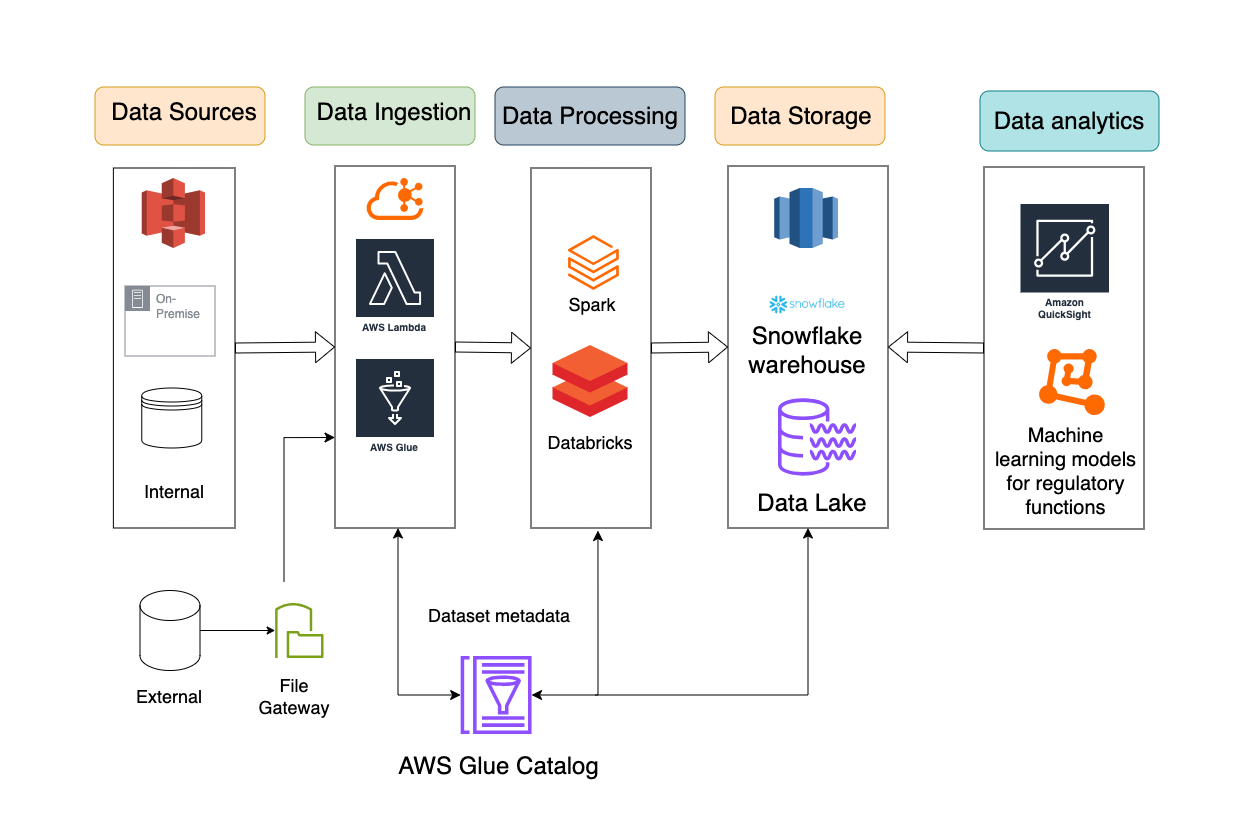
Architecture Components
1. Data Sources (Structured and Unstructured)
- Financial transactions
- Customer and credit data
- Compliance data
- External feeds (sanctions, market data, etc.)
2. Data Ingestion Layer
- AWS Glue/Apache Kafka for real-time ingestion
- AWS Lambda for event-driven processing
- Amazon S3 for raw data storage
3. Data Processing and Quality Validation
- Databricks/AWS EMR for batch data processing
- Apache Spark for large-scale transformations
4. Metadata and Data Lineage Management
-
AWS Glue Data Catalog
5. Data Storage and Warehousing
- Amazon Redshift/Snowflake for structured risk data
- Amazon S3 (LakeHouse Architecture)
- Data Lake
6. Data Quality Monitoring and Alerts
- AWS CloudWatch/Prometheus for monitoring
- Custom dashboards using Amazon QuickSight/Power BI
7. Risk and Compliance Reporting
- ML-powered anomaly detection for risk scoring
- Self-service analytics using Databricks SQL/AWS Athena
Benefits of Cloud Native Solution
- Accurate data for monitoring and detection to ensure better data quality. This will enable accurate reporting for compliance with regulatory requirements.
- Seamless capture of metadata required for data management functions.
- Efficient risk management through system controls avoids manual errors, allowing key performers to focus on tasks requiring judgment.
Each of the above architecture components has to be detailed out with multiple design patterns to support different use cases.
For example, let’s look at the data ingestion layer:
Data Ingestion Challenges
- The ability to access data from disparate systems within and outside the institution can be quite cumbersome, given that data formats, data types, and data storage might be different.
- Transform each source as per compliance needs.
- A lot of risk functions may require past data availability, which may have been in different formats, given changes in the technology landscape in the last few years. For example, data storage can be on the cloud or on-premises.
Let’s see how we can solve this problem of disparate data sources by standardizing the data ingestion layer.
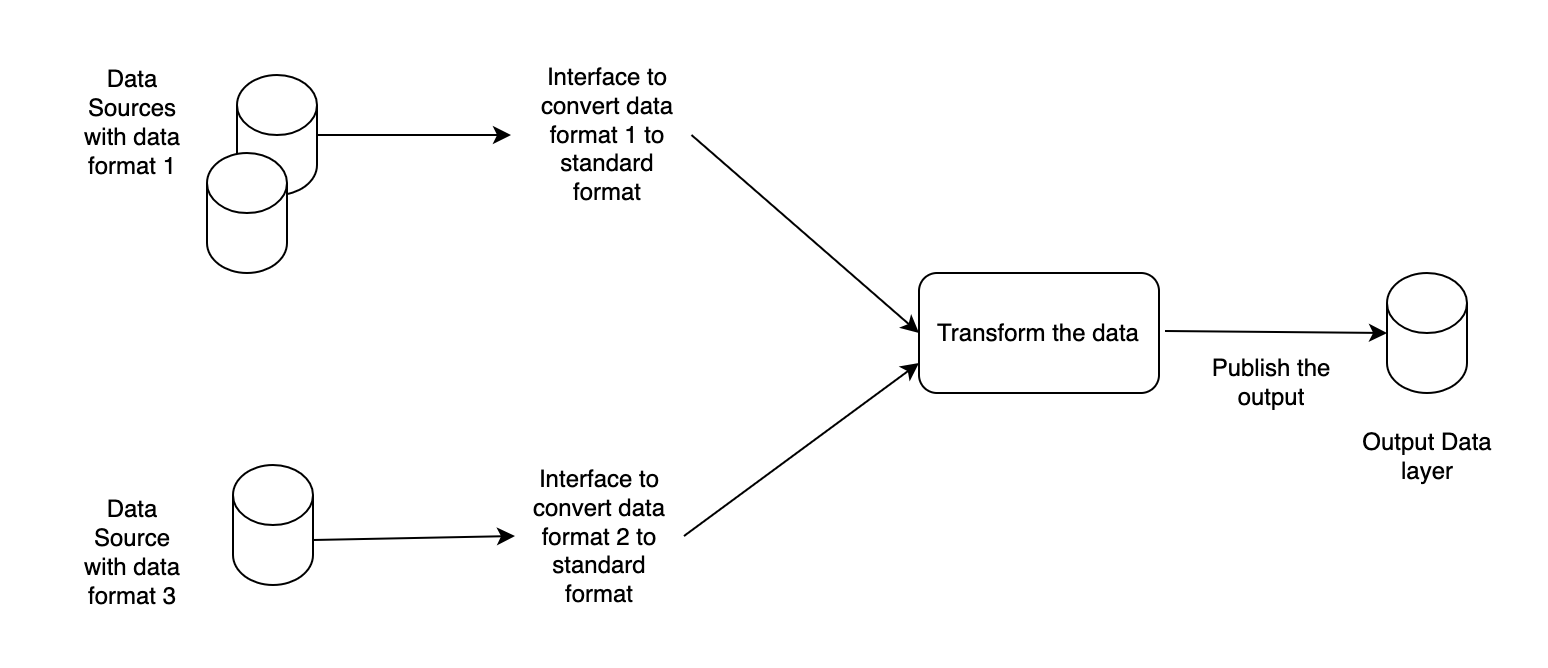
Approach 1: Convert the Data From Different Departments into a Consistent Format
This can be achieved by building interfaces to convert different types of source data into one consistent format.
Pros
- Abstract any source changes only at the interface layer, where source data is read and transformed to a consistent format.
- Standardized format for output data.
Cons
- Additional data persistence layers might be required. This will increase the need to put controls on data processing.
- Defining a common format given the volume and size of the data may vary, depending on different needs.
The diagram below shows the standardization approach 1.
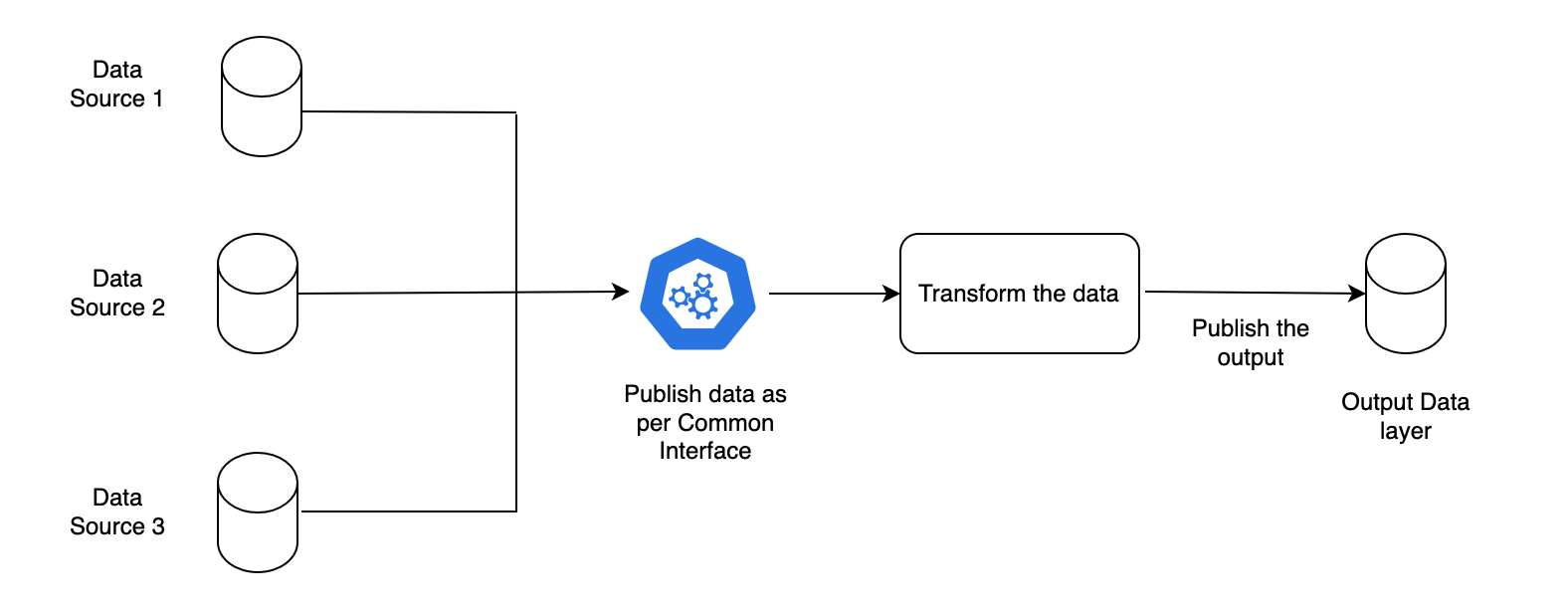
Approach 2: Define a Common Interface to Ingest the Data for Risk Management Usage
Pros
-
Avoids duplicated transformations for each source.
Cons
- Defining common format given the volume and size of the data may vary as per different needs.
- Building alignment from each department to publish data in the requested format.
The diagram below shows the standardization approach 2.
Below is a simple example in Python to create a data ingestion layer if input formats are CSV, JSON, and Parquet.
# Example for data Ingestion API using python, flask
from flask import Flask, request, jsonify
import pandas as pd
app = Flask(__name__)
# Function to read data from various source formats like CSV, json or parquet
def read_data(file_path, file_type):
if file_type == 'csv':
return pd.read_csv(file_path)
elif file_type == 'json':
return pd.read_json(file_path)
elif file_type == 'parquet':
return pd.read_parquet(file_path)
else:
raise ValueError(f"Unsupported file type: {file_type}")
# Publisher function. Target could be a database or lake or kafka topic, etc)
def publish_data(dataframe, target_system):
# Any transformation if needed
# Authentication with target
# Push data
print(f"Publishing to {target_system}...")
# Example: dataframe.to_sql(...)
return True
# API endpoint for ingestion
@app.route('/ingest', methods=['POST'])
def ingest_data():
try:
# Extract parameters
file_type = request.args.get('type') # csv, json, parquet
target_system = request.args.get('target') # e.g., 's3', 'database', 'kafka topic'
uploaded_file = request.files['file'] # multipart form-data
# Save temporarily
file_path = f"/tmp/{uploaded_file.filename}"
uploaded_file.save(file_path)
# Read and publish
df = read_data(file_path, file_type)
success = publish_data(df, target_system)
return jsonify({"status": "success" if success else "failure"}), 200
except Exception as e:
return jsonify({"status": "error", "message": str(e)}), 400
#
if __name__ == "__main__":
app.run(debug=True)The above example is very basic as it does not perform input validation or include error handling. It’s provided to demonstrate that these steps can be easily accomplished with open-source and cloud-native services.
A similar pattern can be followed for other architecture components mentioned above.
Key Takeaways
- Implementing cloud native architecture will integrate data management into the data lifecycle. This will benefit internal users as the required data will be available to them in an automated manner. Better user experience as they are freed up to focus on key tasks required to complete regulatory reporting.
- Improved data management will aid in reducing data quality errors, which will enable machine learning/AI model development and adoption.


!["STOP Using Cold Wallets!" [Web3 SCAM EXPLAINED]](https://wiredgorilla.com.au/wp-content/uploads/2025/12/stop-using-cold-wallets-web3-scam-explained.jpg)


![Scammers Tipped Off? [Short]](https://wiredgorilla.com.au/wp-content/uploads/2025/03/scammers-tipped-off-short.jpg)