Kubernetes has steadily evolved into an industry standard for container orchestration, powering platforms from small developer clusters to hyperscale AI and data infrastructures. Every new release introduces features that not only make workloads easier to manage but also improve performance, cost efficiency, and resilience.
With the v1.34 release, one of the standout enhancements is the introduction of traffic distribution preferences for Kubernetes Services. Specifically:
- PreferSameNode: route traffic to the same node as the client pod if possible.
- PreferSameZone: routing traffic by giving preference to endpoints in the same topology zone before going for cross-zone.
These policies add smarter, locality-aware routing to Service traffic distribution. Instead of treating all pods equally, Kubernetes can now prefer pods that are closer to the client, whether on the same node or in the same availability zone (AZ).
This change is simple, but it has meaningful implications for performance-sensitive and cost-sensitive workloads, particularly in large multi-node and multi-zone clusters.
Traffic Distribution Significance
Traditionally, a Kubernetes Service balances traffic evenly across all endpoints/pods that match its selector. This even traffic distribution is simple, predictable, and works well for most use cases.
However, it does not take into consideration topology, the physical or logical placement of pods across nodes and zones.
Round-Robin Challenges
- Increased latency: If a client pod on Node A routes to a Service endpoint on Node B (or worst case to a different zone), the extra network hop adds milliseconds of delay.
- Cross-zone costs: In cloud environments, cross-az traffic is often billed by cloud providers; even a few mb’s of cross-zone traffic across thousands of pods can rack up significant costs.
- Cache inefficiency: Some ML inference services cache models in memory per pod. If requests bounce across pods randomly, cache hit rates increase, hurting both performance and resource efficiency.
What’s New in Kubernetes v1.34
The new trafficDistribution field, Kubernetes services now support an optional field under spec:
spec:
trafficDistribution: PreferSameNode | PreferSameZone- Default behavior (if unset): traffic is still distributed evenly across all endpoints.
- PreferSameNode: The kube-proxy (or service proxy) will attempt to send traffic to pods running on the same node as the client pod. If no such endpoints are available, it falls back to zone-level or cluster-wide balancing.
- PreferSameZone: The proxy will prioritize endpoints within the same topology zone as the client pod. If none are available, it falls back to cluster-wide distribution.
Traffic Distribution High-Level Diagram
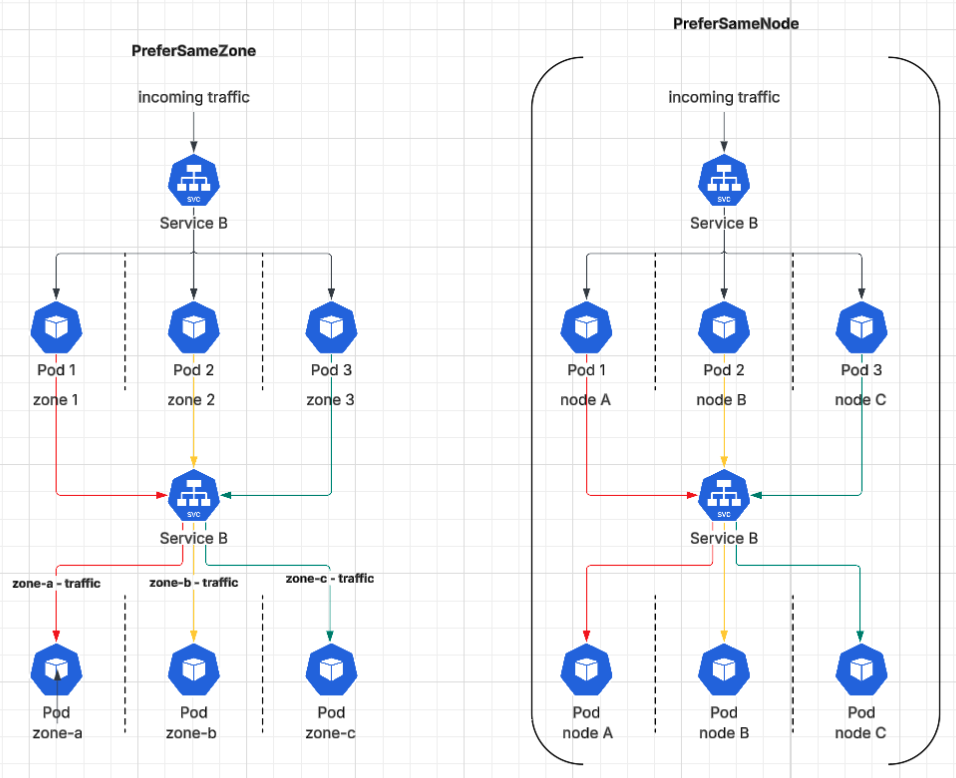
These preferences are optional, and if no preference is specified, then by default, the traffic will be evenly distributed across all endpoints in the cluster.
Benefits
- Lower latency: Requests take fewer network hops when served locally on the same node or within the same zone. This is especially critical for microservices with low SLA requirements or ML workloads where inference times are measured in milliseconds.
- Reduced costs: Cloud providers typically charge for cross-zone traffic. Routing to local pods first avoids these charges unless necessary.
- Improved cache utilization: Workloads such as ML inference pods often keep models, embeddings, or feature stores warm in memory, with the same node routing, which increases cache hit rates.
- Built-in fault tolerance: Both policies are preferences, not hard requirements. If no local endpoints exist due to a node being drained or a zone outage, then Kubernetes seamlessly falls back to cluster-wide distribution.
Use Cases
- ML inference services cache warm models in the pod.
- Distributed systems where data nodes align with zones.
- Larger orgs deploying across multiple AZs can achieve smart failover as traffic stays local under normal conditions, but failover seamlessly if the zone experiences an outage.
Demo Walkthrough
We will try to cover traffic distribution scenarios — default, PreferSameZone, PreferSameNode, and fallback — in the demo below.
Demo: Set Up Cluster, Deploy Pods, Services, and Client
Step 1: Start a multi-node cluster on minikube and label the nodes with zones:
minikube start -p mnode --nodes=3 --kubernetes-version=v1.34.0
kubectl config use-context mnode
kubectl label node mnode-m02 topology.kubernetes.io/zone=zone-a --overwrite
kubectl label node mnode-m03 topology.kubernetes.io/zone=zone-b --overwrite

Step 2: Deploy the echo app with two replicas and the echo service.
# echo-pod.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo
spec:
replicas: 2
selector:
matchLabels:
app: echo
template:
metadata:
labels:
app: echo
spec:
containers:
- name: echo
image: hashicorp/http-echo
args:
- "-text=Hello from $(POD_NAME)"
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
ports:
- containerPort: 5678
# echo-service.yaml
apiVersion: v1
kind: Service
metadata:
name: echo-svc
spec:
selector:
app: echo
ports:
- port: 80
targetPort: 5678
kubectl apply -f echo-pod.yaml
kubectl apply -f echo-service.yaml
# verify pods are running on separate nodes and zones
kubectl get pods -l app=echo -o=custom-columns=NAME:.metadata.name,NODE:.spec.nodeName --no-headers
| while read pod node; do
zone=$(kubectl get node "$node" -o jsonpath='{.metadata.labels.topology.kubernetes.io/zone}')
printf "%-35s %-15s %sn" "$pod" "$node" "$zone"
done
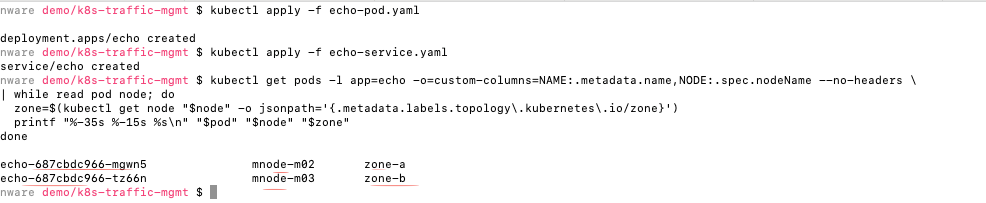
As you can see in the screenshot below, two echo pods spin up on separate nodes (mnode-m02, mnode-m03) and availability zones (zone-a, zone-b).
Step 3: Deploy a client pod in zone A.
# client.yaml
apiVersion: v1
kind: Pod
metadata:
name: client
spec:
nodeSelector:
topology.kubernetes.io/zone: zone-a
restartPolicy: Never
containers:
- name: client
image: alpine:3.19
command: ["sh", "-c", "sleep infinity"]
stdin: true
tty: true
kubectl apply -f client.yaml
kubectl get pod client -o=custom-columns=NAME:.metadata.name,NODE:.spec.nodeName --no-headers
| while read pod node; do
zone=$(kubectl get node "$node" -o jsonpath='{.metadata.labels.topology.kubernetes.io/zone}')
printf "%-35s %-15s %sn" "$pod" "$node" "$zone"
done

Client pod is scheduled on node mnode-m02 in zone-a.
Step 4: Set up a helper script in the client pod.
kubectl exec -it client -- sh
apk add --no-cache curl jq
cat > /hit.sh <<'EOS'
#!/bin/sh
COUNT="${1:-20}"
SVC="${2:-echo}"
PORT="${3:-80}"
i=1
while [ "$i" -le "$COUNT" ]; do
curl -s "http://${SVC}:${PORT}/"
| jq -r '.env.POD_NAME + "@" + .env.NODE_NAME'
i=$((i+1))
done | sort | uniq -c
EOS
chmod +x /hit.sh
exit
Demo: Default Behavior
Form client shell run script: hit.sh to generate traffic from client pod to echo service.
/hit.sh 20
Behavior: In the below screenshot, you can see traffic routed to both pods (10 requests each) in round-robin style.
Demo: PreferSameNode
Patch echo service definition spec to add/patch traffic distribution: PreferSameNode.
kubectl patch svc echo --type merge -p '{"spec":{"trafficDistribution":"PreferSameNode"}}'
Form client shell run script:hit.sh to generate traffic from client pod to echo service.
/hit.sh 40Behavior: Traffic should get routed to pod:echo-687cbdc966-mgwn5@mnode-m02 residing on the same node:mnode-m02 as client pod.



Demo: PreferSameZone
Update echo service definition spec to add/patch traffic distribution: PreferSameNode
kubectl patch svc echo --type merge -p '{"spec":{"trafficDistribution":"PreferSameZone"}}'Form client shell run script:hit.sh to generate traffic from client pod to echo service.
/hit.sh 40Behavior: traffic should get routed to the pod residing in the same zone (zone-a) as the client pod.



Demo: Fallback
Force all echo pods to zone-b, then test again:
kubectl scale deploy echo --replicas=1
kubectl patch deploy echo --type merge -p
'{"spec":{"template":{"spec":{"nodeSelector":{"topology.kubernetes.io/zone":"zone-b"}}}}}'
kubectl rollout status deploy/echo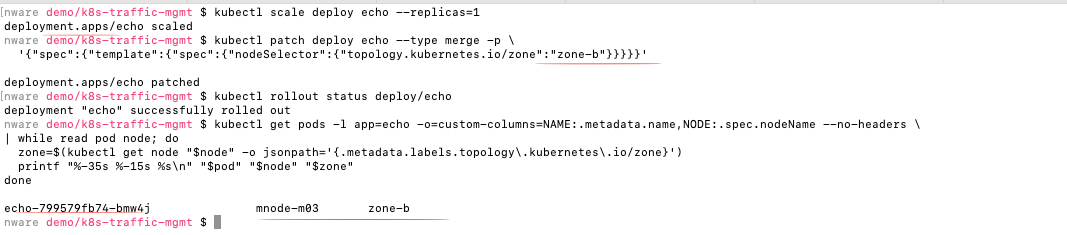
Form client shell run script:hit.sh to generate traffic from client pod to echo service.


Result Summary
| policy | behavior |
|---|---|
|
Default |
Traffic distributed across all endpoints in round-robin fashion. |
|
PreferSameNode |
Prefers pods on the same node, falls back if none available. |
|
PreferSameZone |
Prefers pods in the same zone, falls back if none available. |
Conclusion
Kubernetes release v1.34 adds two small but impactful capabilities: PreferSameNode and PreferSameZone, these preferences helps developers and k8s operators to make traffic routing smarter, ensuring traffic prioritizes local endpoints while maintaining resiliency with fallback mechanism.